Keda Autoscaling for kafka consumers
Intro kubernetes event driven autoscaler
KEDA, which stands for Kubernetes-based Event-Driven Autoscaler, is an open-source project that provides a way to automatically scale Kubernetes deployments based on the number of incoming events or messages from a message queue or streaming platform. This autoscaler can be used with any Kubernetes cluster and supports a wide range of event sources, such as Azure Event Hubs, Apache Kafka, RabbitMQ, and many others. KEDA is designed to be highly customizable and flexible, with support for a variety of scaling triggers, such as CPU usage, memory usage, custom metrics, and external event sources. It also provides advanced scaling features, such as scaling to zero and scaling up based on a custom metric or external trigger.Overall, KEDA makes it easier for developers to build event-driven applications on Kubernetes by providing a simple and scalable way to handle incoming events and automatically adjust the resources allocated to the application.
KEDA kafka Scalers
Scale applications based on an Apache Kafka topic or other services that support Kafka protocol. In the earlier blogs we created a strimzi kafka cluster and created producers and consumers for producing message to kafka and consumers for consuming messages from them. We are now using KEDA based kafka scalers to automatically increase the number of consumers based on the messages produced by kafka producers. The trigger specification for kafka consumers can be done as
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: kafka-consumer-scaler
namespace: default
spec:
scaleTargetRef:
name: kafka-consumer
minReplicaCount: 0
pollingInterval: 10
maxReplicaCount: 5
cooldownPeriod: 30
triggers:
- type: kafka
metadata:
bootstrapServers: k8s-kafka-cluster-kafka-bootstrap.kafka:9092
topic: my-topic
consumerGroup: python-consumer-group
lagThreshold: "10"
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 60
policies:
- type: Pods
value: 1
periodSeconds: 60
One significant thing to note about the autoscaler config is it downscales the number of kafka consumers based on offset lag threshold set on configuration for autoscaling.
The state of the pods before KEDA based autoscaling kicks in.

The number of kafka producers has been increased via the command
kubectl scale deployment kafka-proudcer --replicas 5
It will add four more replicas to the existing kafka-producer deployment. With increased number of producers the number of consumer increases after KEDA autoscaling kicks in.
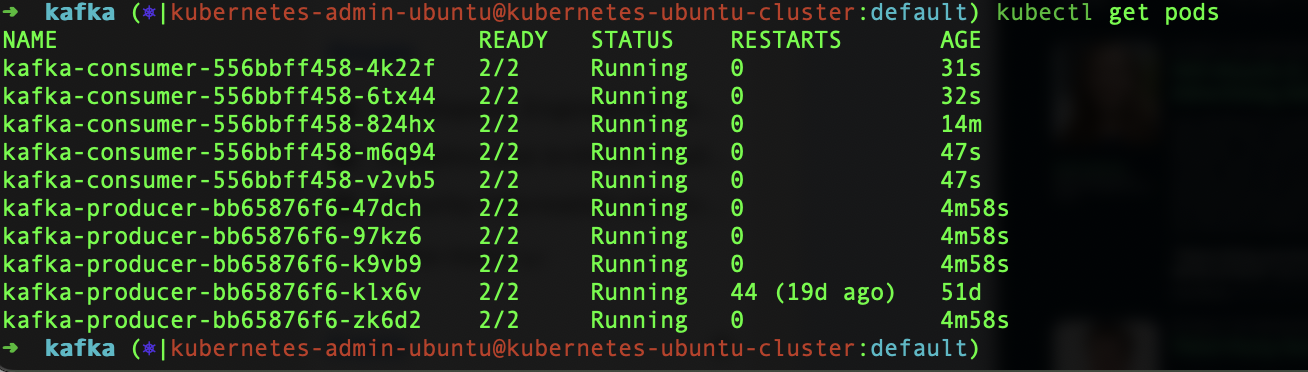
Once the load subsides the number of consumer will go down as well owing to the less demand for the consumers. We can build an automated autoscaling system using KEDA in kubernetes. Also can utilize a vast number of scalers other than what kubernetes Horizontal pod autoscaler provides.